Süni intellekt, xüsusilə dil modelləri son illərdə texnologiyanın ən sürətlə inkişaf edən sahələrindən birinə çevrilmişdir. ChatGPT kimi sistemlər insan dilini anlamaq və yeni mətn yaratmaq qabiliyyətinə malikdir. Bu cür sistemlərin arxasında isə transformer arxitekturasına əsaslanan böyük dil modelləri dayanır. MicroGPT bu böyük modellərin sadələşdirilmiş tədris versiyasıdır və əsas məqsədi GPT tipli modellərin necə işlədiyini addım-addım göstərməkdir. Bu model real GPT sistemlərindən xeyli kiçik olsa da, onun işləmə prinsipi eyni məntiqə əsaslanır. MicroGPT vasitəsilə məlumatın toplanmasından (“data collection”) başlayaraq tokenləşdirmə (“tokenization”), yerləşdirmə (“embedding”), diqqət mexanizmi (“attention mechanism”), modelin təlimi (“training process”) və nəticə generasiyası (“inference generation”) kimi bütün mərhələləri müşahidə etmək mümkündür.

Modelin işləməsinin ilk mərhələsi məlumatın hazırlanmasıdır. Hər bir süni intellekt sistemi öyrənmək üçün məlumatdan istifadə edir. MicroGPT modelində bu məlumatlar ingilis adlarından ibarətdir. Məsələn, sistem “Emma”, “Liam”, “Olivia”, “Dorothy” kimi adları öyrənir. Bu adların hər biri model üçün ayrıca bir sənəd kimi qəbul edilir. Model bu adları analiz edərək hansı hərflərin bir-birinin ardınca gəlmə ehtimalını öyrənir. Məsələn, model öyrənə bilər ki, [E] hərfindən sonra [M] gəlməsi ehtimalı yüksəkdir və “Emma” kimi adlar belə formalaşır. Bu mərhələdə məlumatın çoxluğu və keyfiyyəti çox vacibdir. Məlumat nə qədər çox olarsa model dil strukturunu bir o qədər yaxşı öyrənə bilər.
Məlumat hazır olduqdan sonra növbəti mərhələ tokenləşdirmədir. Dil modelləri mətnlə deyil, rəqəmlərlə və ya hərflərlə işlədiyi üçün sözlər əvvəlcə daha kiçik hissələrə bölünür. Bu hissələr token adlanır. MicroGPT modelində tokenləşdirmə hərf səviyyəsində həyata keçirilir. Məsələn, “Emma” adı modelə daxil edilərkən əvvəlcə xüsusi başlanğıc tokeni əlavə olunur və ardıcıllıq belə görünür: [BOS], [E], [M], [M], [A], [BOS]. Burada BOS ardıcıllığın başlanğıcını göstərən xüsusi simvoldur. Daha sonra hər bir hərf müəyyən bir ədədi identifikatorla əlaqələndirilir. Məsələn [E] bir ID, [M] başqa bir ID, [A] isə başqa bir ID ilə göstərilir. Beləliklə, söz artıq model üçün rəqəmlər ardıcıllığına çevrilmiş olur.
Tokenlər modelə daxil edilməzdən əvvəl onların vektor formasına çevrilməsi lazımdır. Bu proses “embedding” adlanır. Embedding hər bir hərfin və ya tokenin riyazi koordinatlarla təsvir edilməsidir. MicroGPT modelində embedding iki hissədən ibarətdir. Birincisi token embeddingdir, yəni hər bir hərf üçün xüsusi vektor yaradılır. İkincisi isə position embeddingdir. Bu embedding tokenin söz daxilində hansı mövqedə yerləşdiyini göstərir. Məsələn “Emma” sözündə ilk [M] və ikinci [M] eyni hərf olsa da onların mövqeləri fərqlidir. Buna görə model mövqeni də nəzərə almalıdır. Token embedding və position embedding birlikdə toplanaraq final embedding vektorunu yaradır. Nəticədə hər bir token üçün müxtəlif rəqəmlərdən ibarət vektor yaranır və bu vektor modelin giriş məlumatına çevrilir.
Embedding mərhələsindən sonra transformer modelinin əsas hissəsi olan attention mexanizmi işləməyə başlayır. Attention mexanizmi modelə ardıcıllıq daxilində hansı elementlərin daha vacib olduğunu müəyyən etməyə kömək edir. Bu mexanizm Query, Key və Value adlı üç komponentdən istifadə edir. Embedding vektoru bu üç vektora çevrilir və model onların köməyi ilə tokenlər arasındakı əlaqəni hesablayır. Məsələn model “Emma” sözünü analiz edərkən ikinci [M] hərfinin əvvəlki [E] və [M] hərfləri ilə əlaqəsini nəzərə alır. Bu proses nəticəsində model hər token üçün yeni kontekstual vektor yaradır. Müxtəlif attention head’ləri fərqli hesablamalar aparır və nəticədə model daha zəngin məlumat əldə edir.
Model bu məlumatı istifadə edərək növbəti tokeni proqnozlaşdırır. Dil modelinin əsas məqsədi növbəti tokeni təxmin etməkdir. Məsələn modelə [BOS] və [E] tokenləri verildikdə model növbəti hərfin hansı ola biləcəyini hesablayır. Ehtimal paylanmasında müxtəlif hərflər üçün fərqli ehtimallar yaranır. Model məsələn [E] üçün 0.050 ehtimal, [M] üçün isə 0.053 ehtimal verə bilər. Ən yüksək ehtimalı olan token modelin seçimi olur. Bu proses hər addımda təkrarlanaraq sözün davamı formalaşır.
Modelin proqnozunun nə qədər doğru olduğunu ölçmək üçün loss funksiyası istifadə olunur. Loss modelin səhvini ölçən riyazi göstəricidir. Hər mövqe üçün ayrıca loss hesablanır. Məsələn POS0 üçün loss 2.998, POS1 üçün 2.937 və POS2 üçün 4.506 kimi dəyərlər ola bilər. Bu dəyərlərin ortalaması isə final loss olur. Əgər model düzgün tokenə yüksək ehtimal verirsə loss kiçik olur, əks halda loss böyük olur. Loss nə qədər kiçik olarsa modelin proqnozu bir o qədər düzgün hesab olunur.
Loss hesablandıqdan sonra model parametrlərinin necə dəyişdirilməli olduğunu müəyyən etmək üçün gradient hesablanır. Gradient hər bir parametrin loss’a necə təsir etdiyini göstərir. Məsələn [E] tokeninin gradient dəyəri mənfi ola bilər və bu modelə həmin parametrin hansı istiqamətdə dəyişməli olduğunu bildirir. Gradient hesablaması backpropagation adlanır . Bu prosesdə error siqnalı modelin bütün qatları boyunca geriyə ötürülür və hər bir parametr üçün gradient dəyəri hesablanır. Daha sonra optimizer alqoritmi bu gradientləri istifadə edərək parametrləri yeniləyir.
Modelin təlim mərhələsində bu proses minlərlə və ya milyonlarla iterasiya ərzində təkrarlanır. Hər iterasiyada model əvvəlcə proqnoz verir, sonra loss hesablanır, gradientlər tapılır və parametrlər yenilənir. Bu təkrar proses nəticəsində model getdikcə daha yaxşı nəticələr əldə edir və daha real mətnlər generasiya edə bilir. Təlim prosesi zamanı learning rate adlı parametr də mühüm rol oynayır. Learning rate parametrlərin nə qədər sürətlə dəyişəcəyini müəyyən edir. Çox böyük learning rate modelin stabil öyrənməsinə mane ola bilər, çox kiçik learning rate isə təlim prosesini çox yavaş edə bilər
Model təlimi tamamlandıqdan sonra inferensiya mərhələsi başlayır. Inferensiya modelin öyrəndiyi məlumatlardan istifadə edərək yeni nəticələr yaratdığı mərhələdir. Bu mərhələdə model tokenləri ardıcıl şəkildə generasiya edir. Məsələn model yeni adlar yaratmaq üçün hər addımda növbəti hərfi seçir və nəticədə yeni söz formalaşır. Proses autoregressiv şəkildə həyata keçirilir, yəni model hər addımda əvvəlki tokenləri giriş kimi istifadə edərək növbəti tokeni proqnozlaşdırır. Bu prosesdə temperature adlı parametr də istifadə olunur. Temperature dəyəri modelin nə qədər kreativ olacağını müəyyən edir. Temperature aşağı olduqda model daha stabil və oxşar nəticələr yaradır, yüksək olduqda isə daha müxtəlif nəticələr generasiya edir.
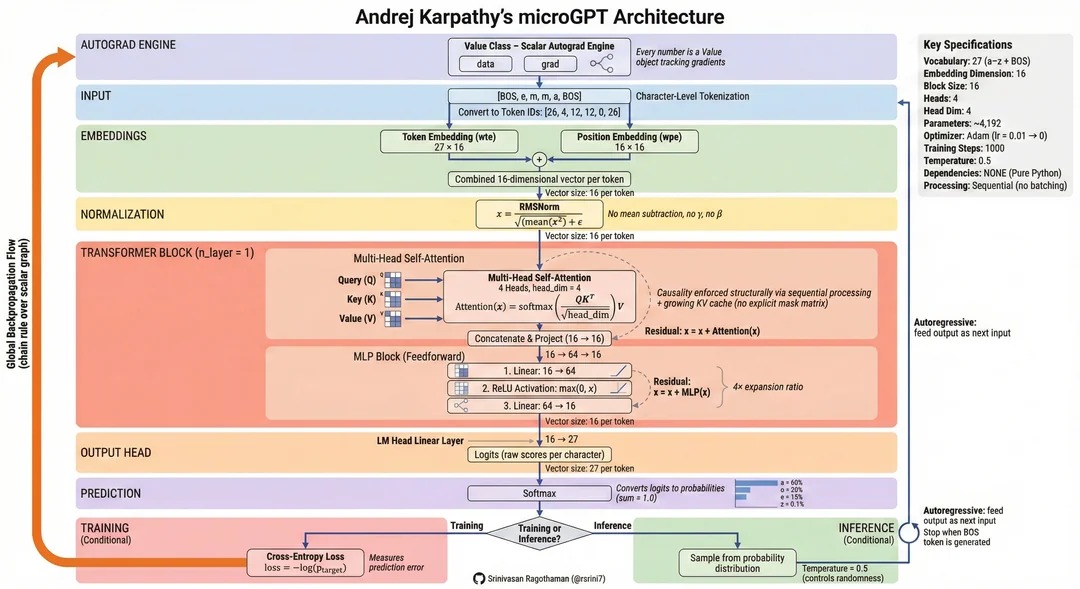
MicroGPT modeli real GPT sistemləri ilə eyni prinsipə əsaslansa da ölçü baxımından çox kiçikdir. Real GPT modelləri milyardlarla parametrdən ibarət olur və trilyonlarla token üzərində təlim keçir. Bundan əlavə real sistemlər daha mürəkkəb tokenləşdirmə üsullarından istifadə edir və böyük hesablama infrastrukturlarında işləyir. Buna baxmayaraq MicroGPT modeli həmin böyük sistemlərin alqoritmik skeletini göstərir və transformer modellərinin necə işlədiyini anlamaq üçün çox faydalı bir tədris vasitəsidir.
 04 may 2026
04 may 2026
 07 aprel 2026
07 aprel 2026
 20 fevral 2026
20 fevral 2026
 12 fevral 2026
12 fevral 2026
 04 sentyabr 2025
04 sentyabr 2025
 07 may 2025
07 may 2025
 13 may 2024
13 may 2024
 21 sentyabr 2023
21 sentyabr 2023







© 2011-2026 Bütün Hüquqlar Qorunur